
Table of Contents
FAQs
Why can't I see variable transformations in the variable pool?
To see your missing variables, check the View ‘new variable’ suggestions box. Then, numerical transformations and binary transformations of categoricals (like job category or department code) will be displayed. Note that these transformations will always be candidates for the model when building the model automatically, regardless of if the box is checked. Under the default setting (box un-checked), Predict automatically displays any related variables that are continuous or binary (not categorical), however even with the box un-checked, any categorical transformations that enter the model will be visible in the Included Variables section.
What is the difference between a memorized model and a saved analysis?
A memorized model is any model that a user has saved within the scope of an analysis file by clicking the Memorize Model button. Using this options saves the formula of the model inside of Predict.
In order for the model to be used outside of Predict for scoring, the model formula needs to be memorized and then saved individually using the blue save button and saving the model as a .vpsm (Veera Predict Scoring Model) file.
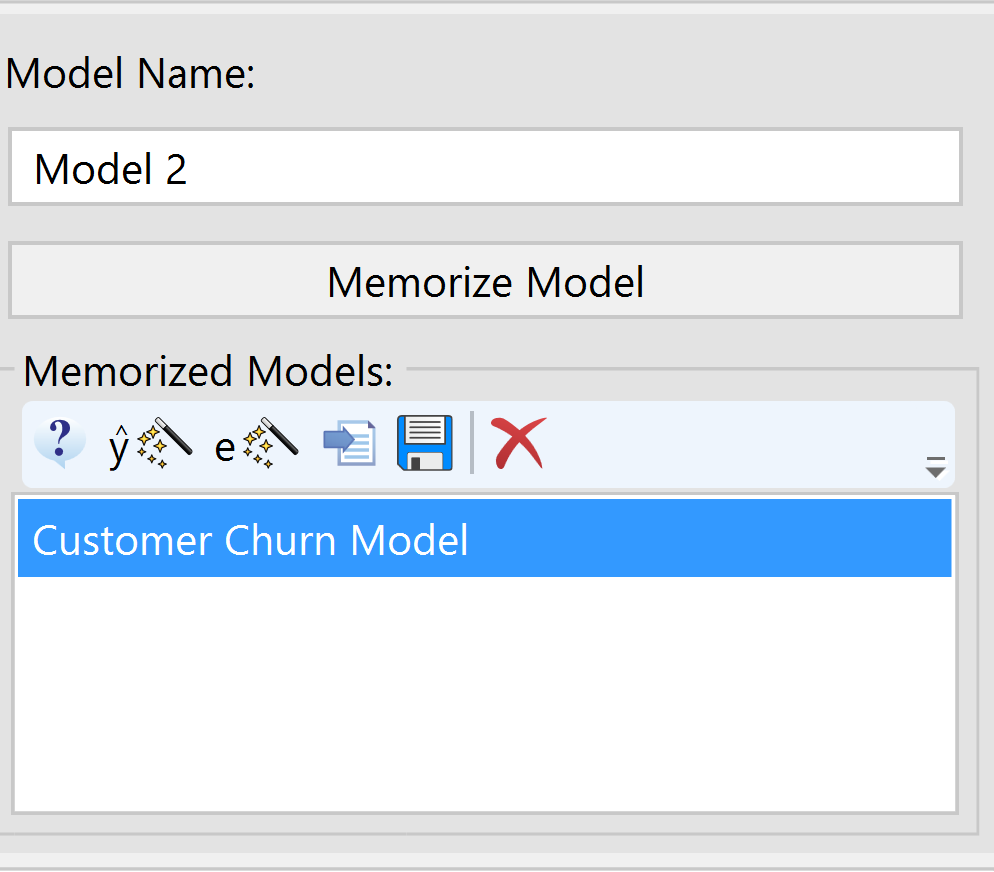
A saved analysis is a file that comprises the data as well as any filters, variables and models you have saved. This option, found by going to File > Save Analysis, saves all the materials externally to Predict in a .vpa (Veera Predict Analysis) file type.
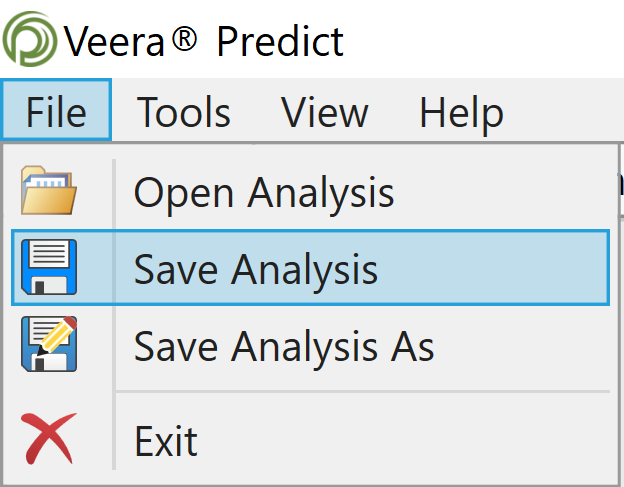
Note: To make edits to a model after closing the software, you need to load the saved analysis file in Predict and then select the memorized model to edit it. You cannot "load" a memorized model into Predict to edit it without having it saved within an analysis.
Can I see how a model is built?
When you build a model automatically, you can see the detailed steps and decisions made by the software in the Model Steps diagnostic pane, found in the very bottom left of the Model subtab. These steps, however, are not stored with the model when you memorize it, so you will be unable to retroactively investigate. To better understand your models, be sure to review models as you build them.
I noticed a value of intercept - what does it mean?
Including an intercept is standard practice in regression modeling. The intercept is a coefficient that ensures every line does not have to be fitted through the (0,0) coordinate. Essentially, it ensures an optimal model fit to the data by not restricting the nature of the variables’ relationships to the predicted outcome.
How can I tell how accurate my model is?
Predict has several features that can be used to test the general accuracy of the model’s performance.
A model’s performance can be gauged depending on its:
- Decile Analysis
- R Square Score
- Percent Concordance
- Actual and Predicted Comparison
If I want to score new records using my model, what variables do I need in the dataset?
When applying scoring models from Predict, you will only need the variables used in the model itself. Even if your original model file contained dozens of variables that did not enter your model, you do not need to include those variables when scoring new records. The scoring dataset can also include any optional descriptive fields as these can help to act on the results more practically.
Troubleshooting
A variable in my dataset did not enter the model
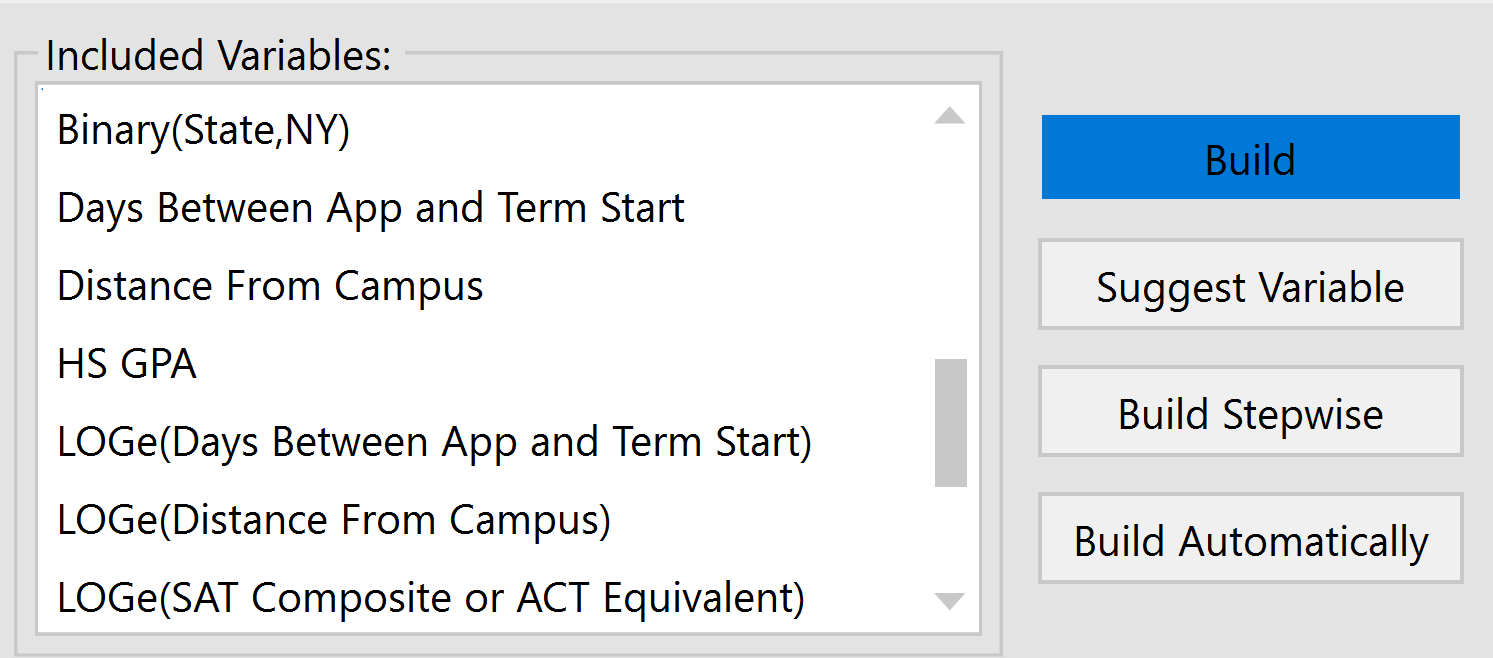
When a model is built, variables that entered the model are displayed in the Included Variables box, while variables that did not enter the model remain in the Variables box. However, the included variables can be cherry-picked to customize the model according to the user's needs.
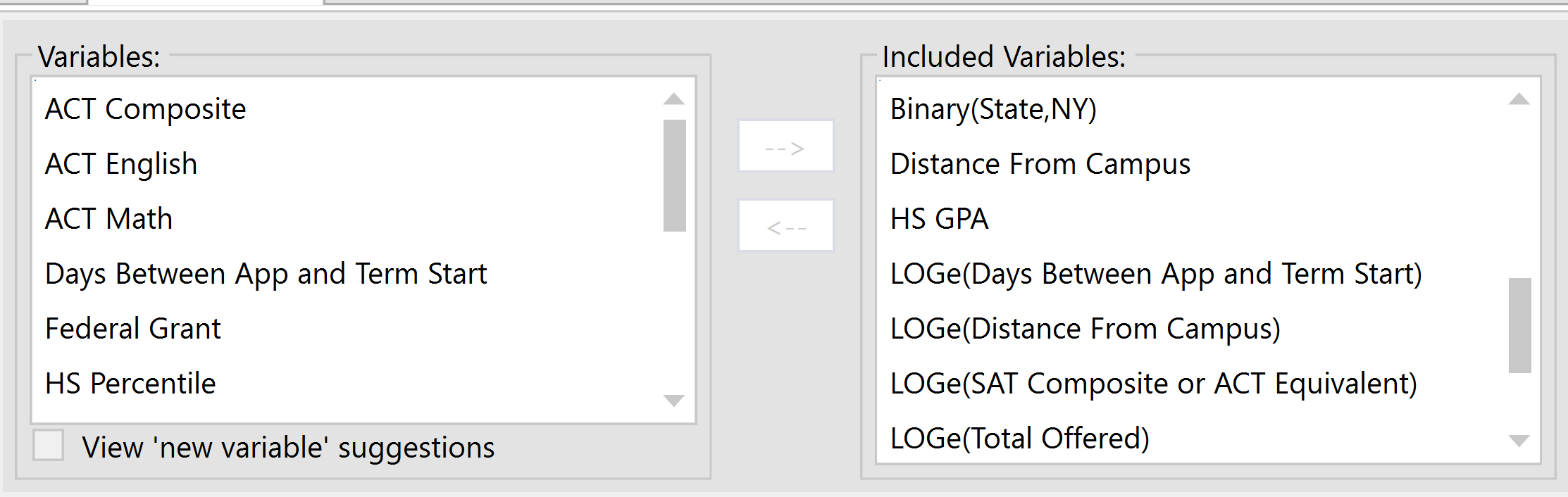
To manually add a variable from the variable pool into the model, simply select the variable from the Variables box, then click the right-pointing arrow (–>) to move it into the Included Variables box.
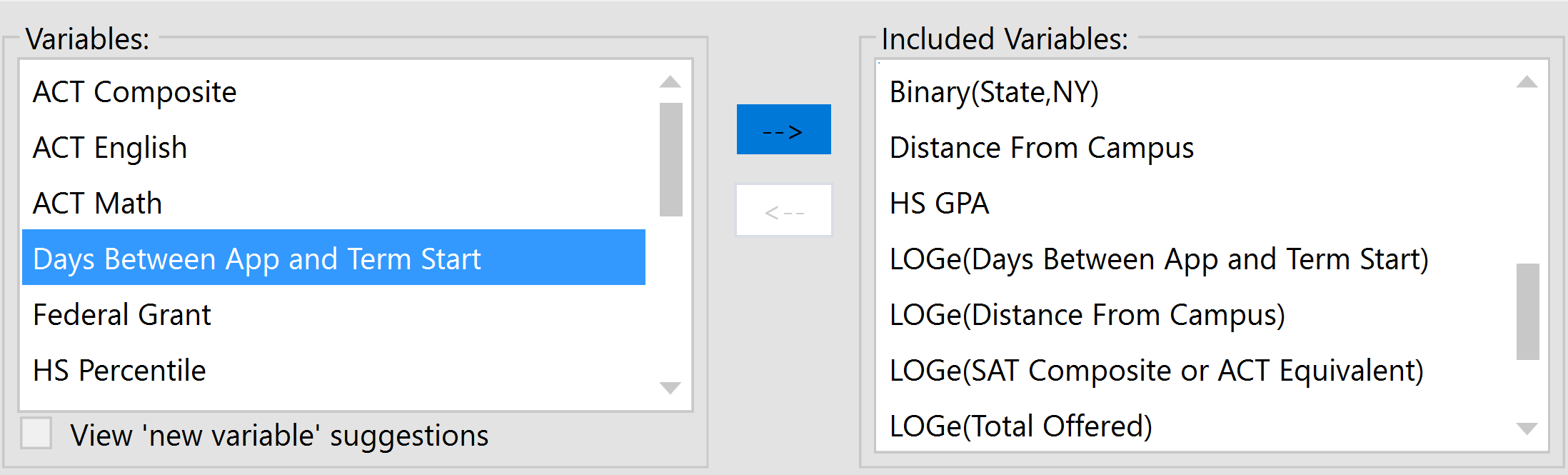
To finish the process, click the Build button.
Note: If you use the Build Automatically button instead of the Build button after manually adding variables to the included variables section, any manual additions may be removed and overridden by the automatic version.
A variable entered the model that makes no sense
Predict will consider any variables of data types Continuous, Binary, or Categorical to enter a model. Sometimes variables fall into one of these data types, but are not truly something that should be considered as having any predictive value.
A common example of this is a Student ID number. ID numbers often enter as a continuous value, and therefore are considered for the model. However the arbitrary string of numbers assigned to a student should not be indicative of whether that student will enroll, retain, graduate, or any other outcome, so this variable should be removed from the variable pool.
To do this, navigate to the Automine tab and locate the variable that should be removed. Right-click on the variable and select "Exclude Variables and their transforms from modeling". This variable will no longer be considered for the modeling variable pool.

I built a model twice with the same dataset and got different results
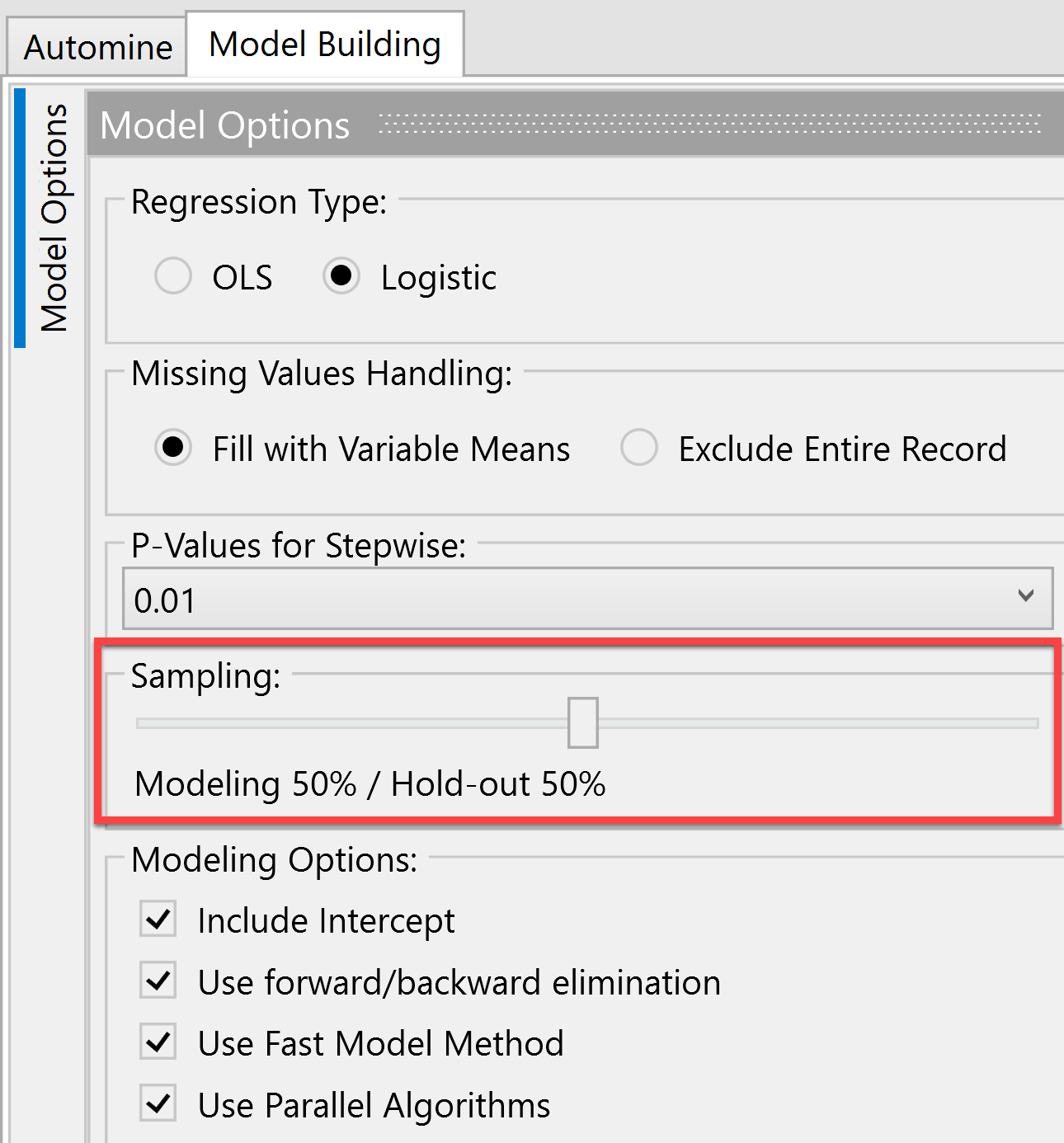
Predict has a feature that allows the use of random samples while building models. This feature is called a holdout sample and the default setting in Predict is a 50%. This means that 50% of the data is used to build the model, and the other 50% is used to validate the model. Reloading a dataset over again means you are very likely to see a different sample of your overall dataset than before. This directly influences the model results, but is nothing to be worried about.
Most of the time you will see the same variables, even if the coefficients change slightly. If you see some variables swap in and out entirely, it mostly likely means that two or more variables compete closely with each other to explain the outcome. We recommend keeping track of which variables swap in and out in cases like these. Then you can see why the two compete so closely, and potentially decide which of the two you’d prefer to have in the model.
Keep in mind that you can adjust the holdout sample settings by going to the Model Options > Sampling. A model without a holdout sample (100% modeling / 0% holdout) will always find the same relationships, so you can avoid any uncertainty by eliminating the holdout sample.
Comments
0 comments
Article is closed for comments.