
About: This article describes the Model subtab in the Analysis tab.
Table of Contents
- Introduction
- Selecting a Y Variable
- Model Building
- Automine Tab
- Final Regression Model
- Model Steps
- Model Visualization
- Create Model Variable
- Saving and Memorizing Models
- Video Tutorials
- Related Articles

Introduction
The Model subtab is where models to predict the Y-variable are built. Predict can build a model automatically or users can manually create their own custom models.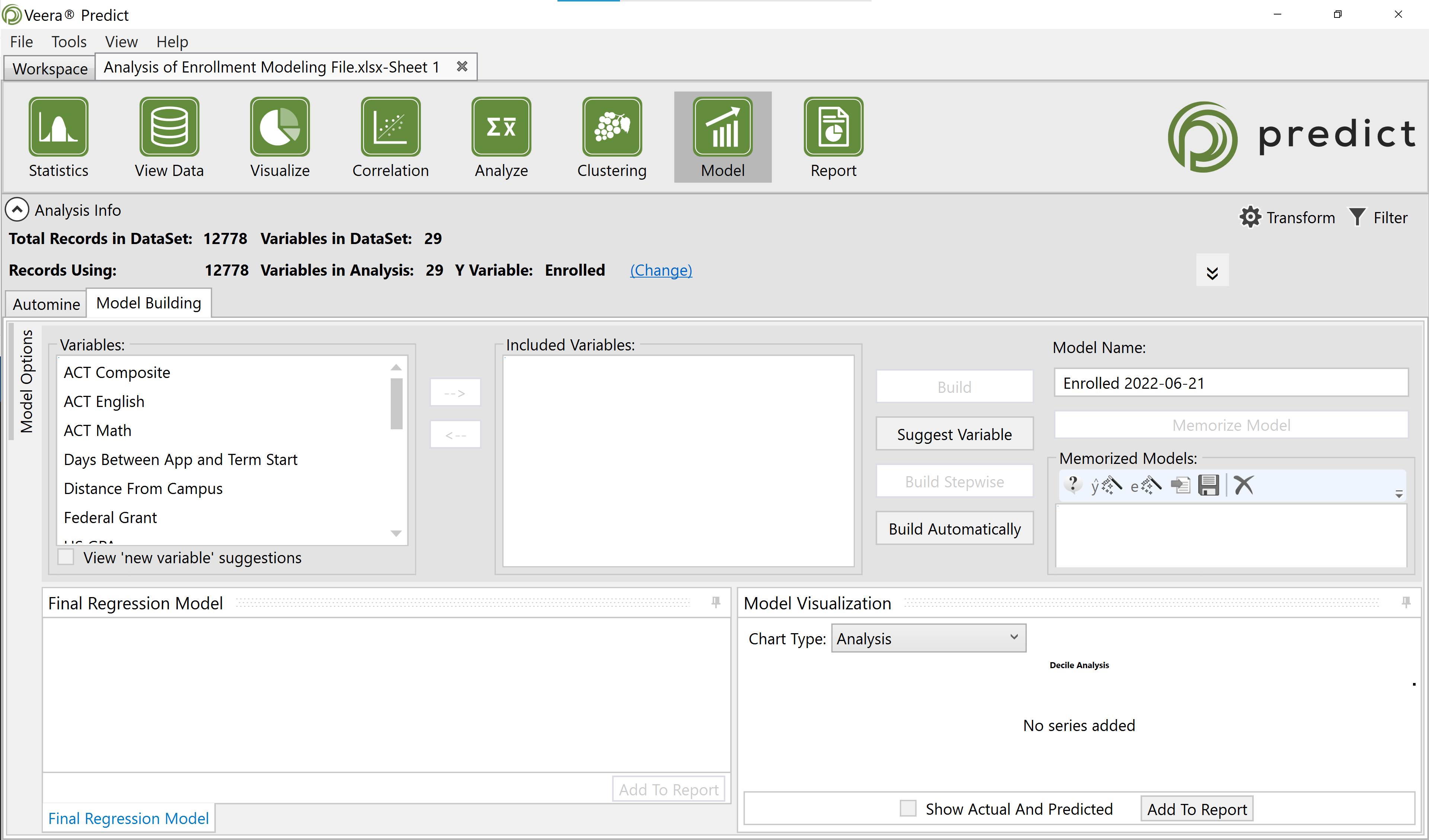
Predict uses regression analysis to develop predictive models. Regression uses several techniques for modeling and analyzing data describing past behavior. More specifically, regression analysis helps explain how the typical value of the Y-variable changes when any one of the other, independent variables is changed, while the other independent variables are held fixed. This is known as a “step.” These series of stepwise results are then combined into a formulaic whole – the predictive model. Predict offers two types of regression analysis – Logistic and OLS (Ordinary Least Squares).
Selecting a Y Variable
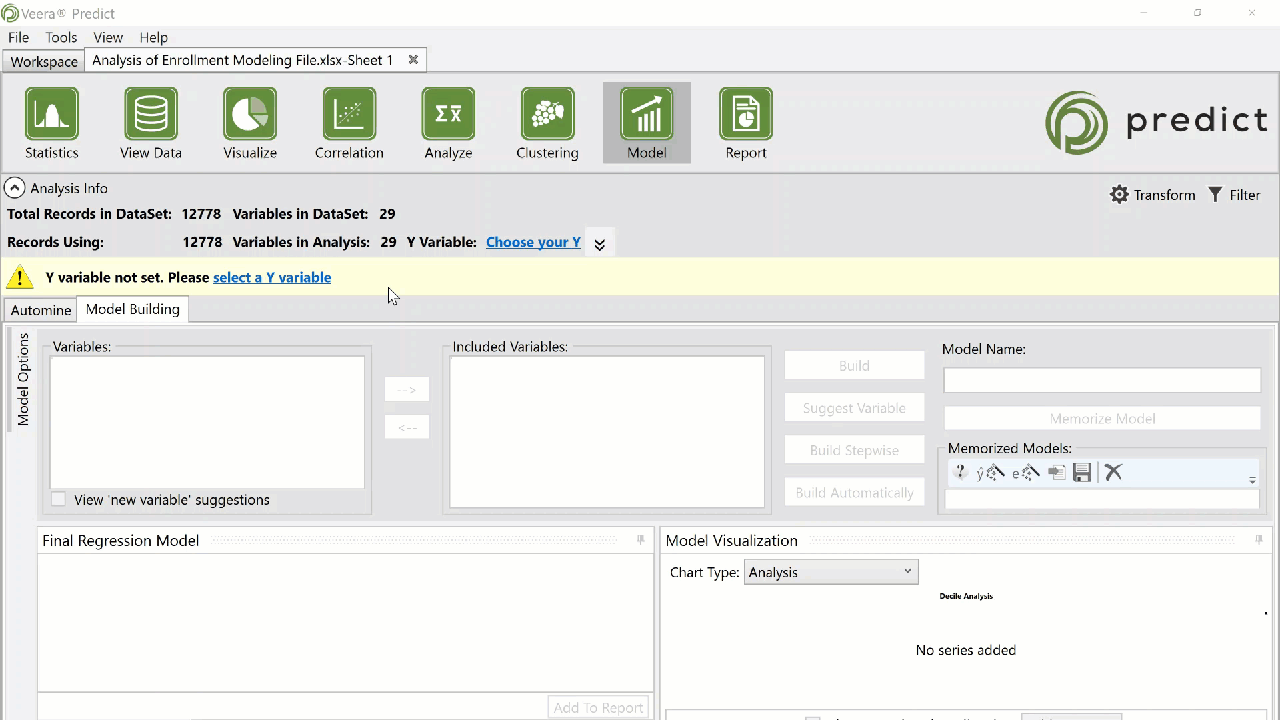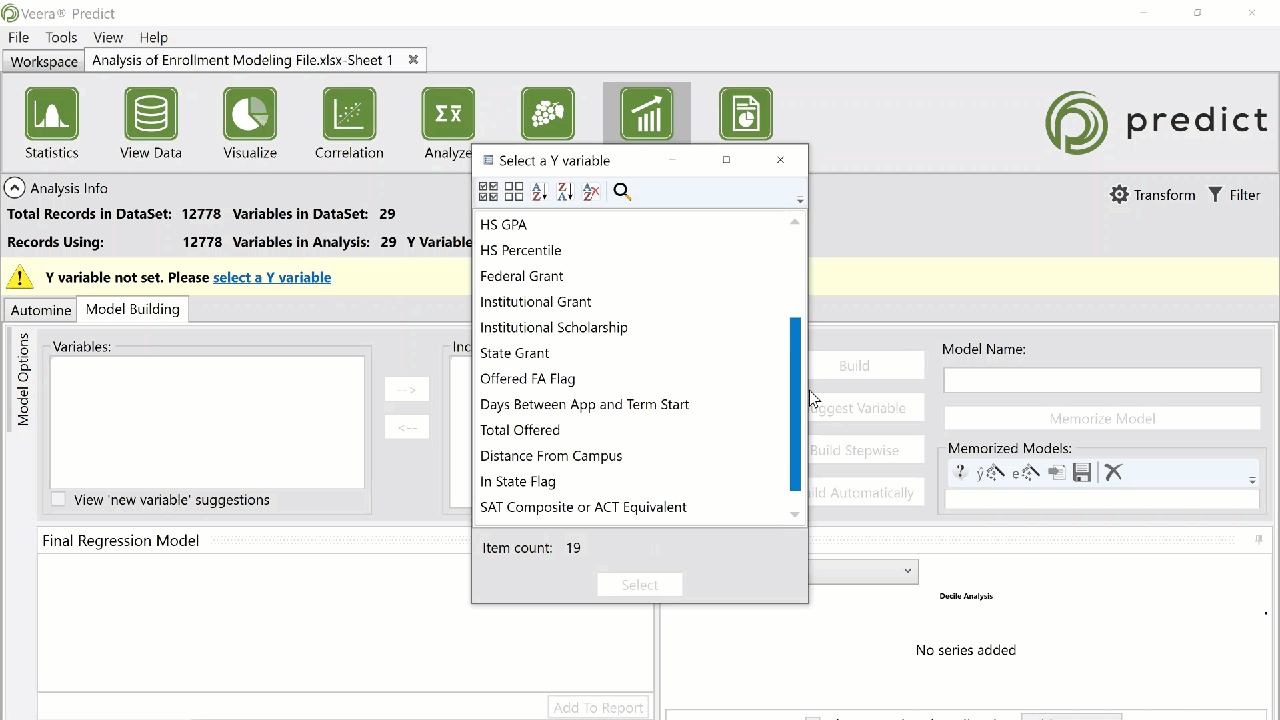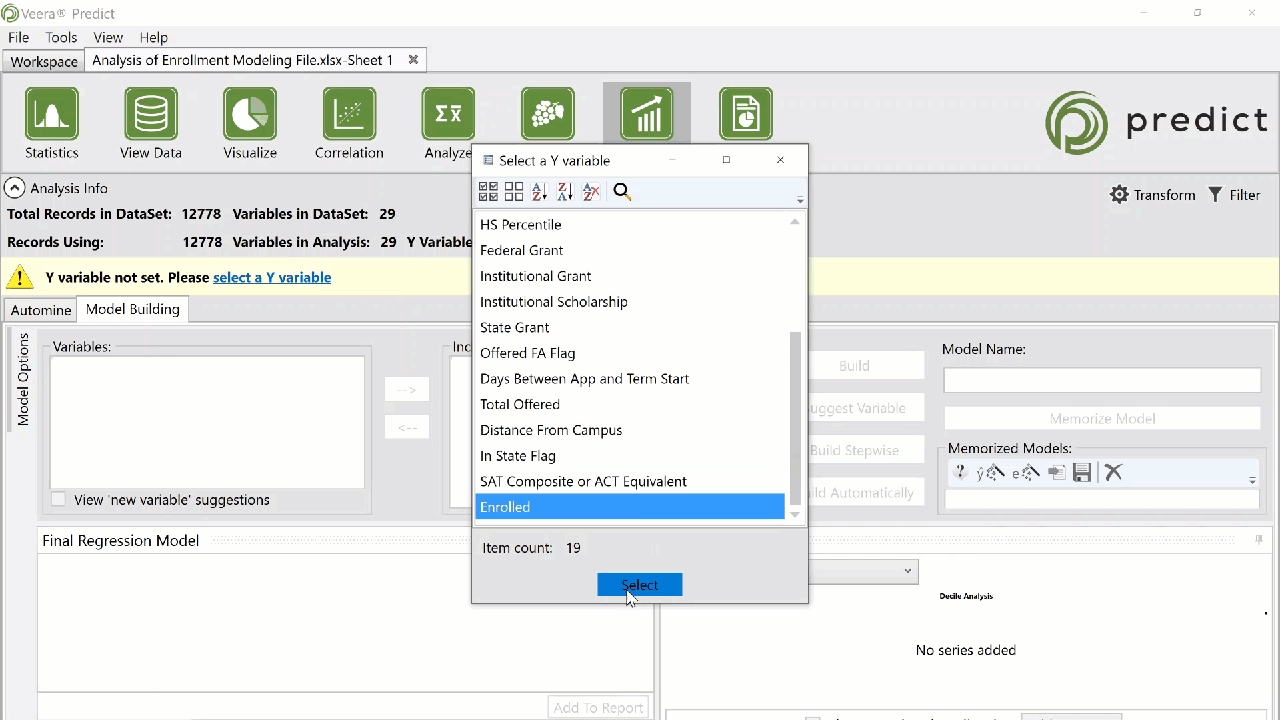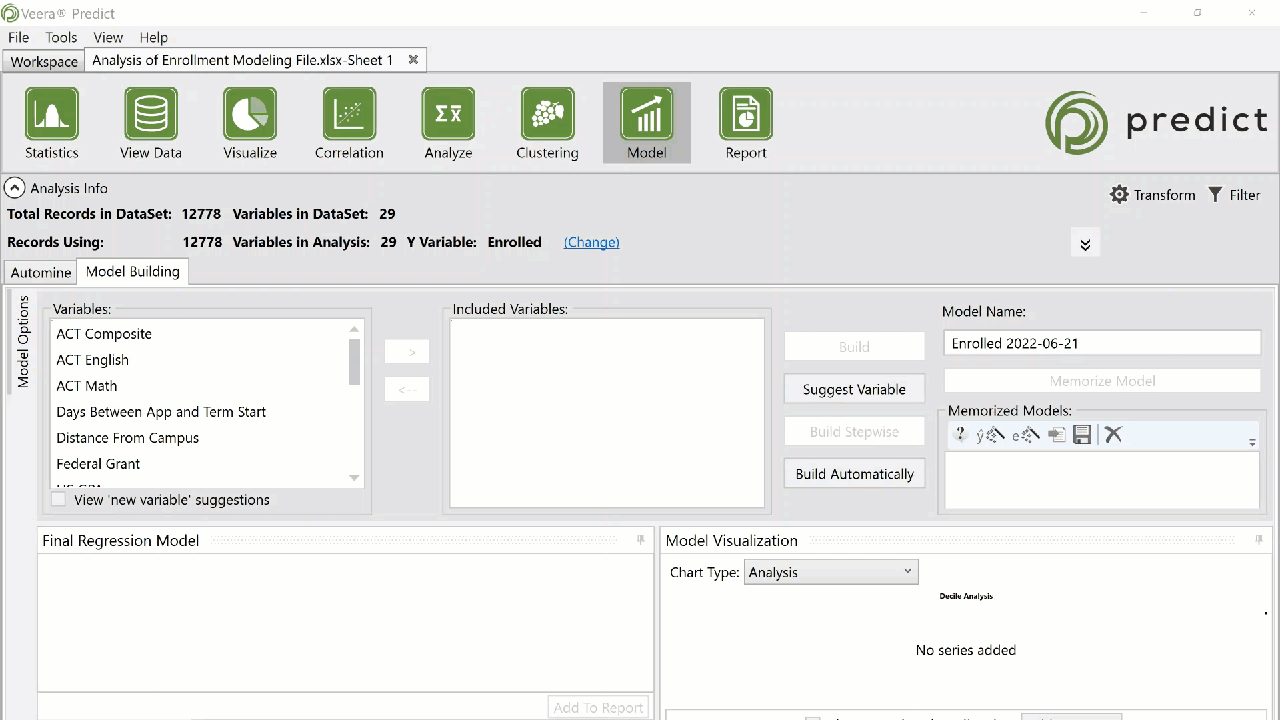
Before a model can be built, the outcome that is being predicted needs to be established. This outcome can also be referred to as the dependent variable or y variable. To define the Y Variable in predict, expand the Analysis Info section and use the Choose your Y or select a Y variable options.

Either option will launch a window allowing users to select any binary or continuous variable from the dataset. The datatype of the selected Y variable will determine which regression type is used to build the model.
Once a y variable is selected, a variable pool is automatically created populating the Variables pane with only the fields that are significantly statistically related to the y variable.
Model Building
Variables List
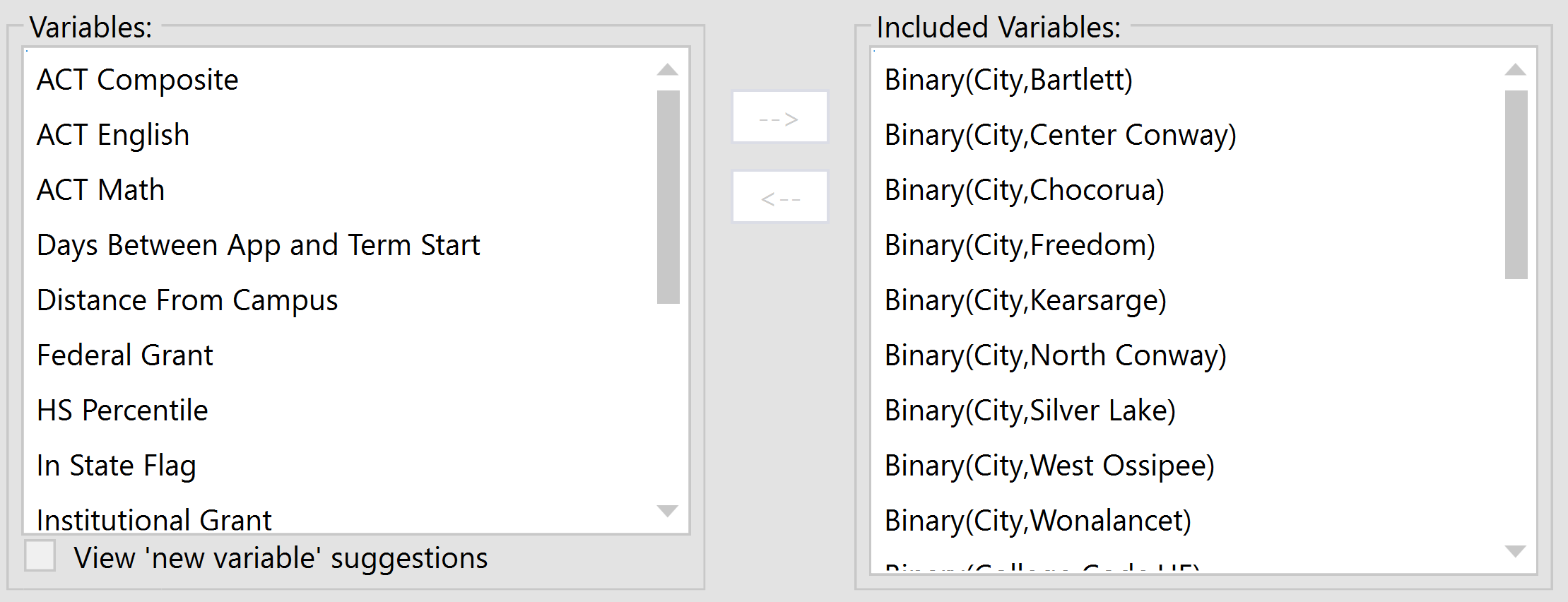
The Model Building tab contains two stages of variables: Variables and Included Variables.
Variables
This is a list of all the variables originally found in the dataset, as well as any variables created as part of the analysis, that are significantly statistically related to the y variable and are to be considered for inclusion in the model. More information on how each variables is determined to be added to the variable pool can be found in the Automine tab.
Note: Not every variable in the original dataset will show in the Variables pane. Variables that were manually excluded during the analysis and those that are automatically disqualified (constants, dates, indexes) will not appear.
Tip: Use the View 'new variable' suggestions box to show transformations of available variables that can also be considered for modeling if found to be predictive.
Included Variables
This is a list of coefficients derived from the Variables list (above). Variables can be manually added or removed from the Included Variables pane by using the right facing arrow, or can be automatically selected when the Build Automatically option is used. Variables in the Included Variables pane at the time the model created, become the coefficients included in the model.
Build Options
Building your model is the process used to take your Variables and applying them toward the regression modeling process. There are several ways to choose which of these Variables are and are not selected in this process.

Build
Users may choose to build their own models by manually adding and/or removing variables. This can be done using the arrows to add or remove variables to the Included Variables pane. Then select Build. The Build option will build the model exactly as configured using only the variables in the Included Variables pane.
Suggest Variable
Clicking the Suggest Variable button allows Predict to decide which variable from the Variables pane has the strongest relationship to the outcome and would best improve the model, and automatically moves that variable to the Included Variables pane. Using this button will always enter just one variable at a time, so it can be used multiple times to repeat the process. This is typically done after building a model manually (see Build above) to see if it can be improved.
Build Stepwise
The Build Stepwise option initiates a process of checking to see if any variables should be dropped from the model following each step of the regression analysis. If a variable that has already entered the model is no longer statistically significant at the chosen p-value, that variable will be removed from the model. This step is usually taken after building a model manually (see Build above) to see if it can be improved.
Build Automatically
The Build Automatically option is recommended as it is the easiest and fastest way to build a model. This option allows Predict to build what it sees as the best model that can be built on the current dataset. It takes all non-linearities in the data into account and makes all of the appropriate transformations on the candidate variables automatically. It is strongly recommended that users Build Automatically when crafting a model. 
Model Options
The Model Options sidebar, which is located on the far left side of the Model Building interface, offers configuration options for the model building process.
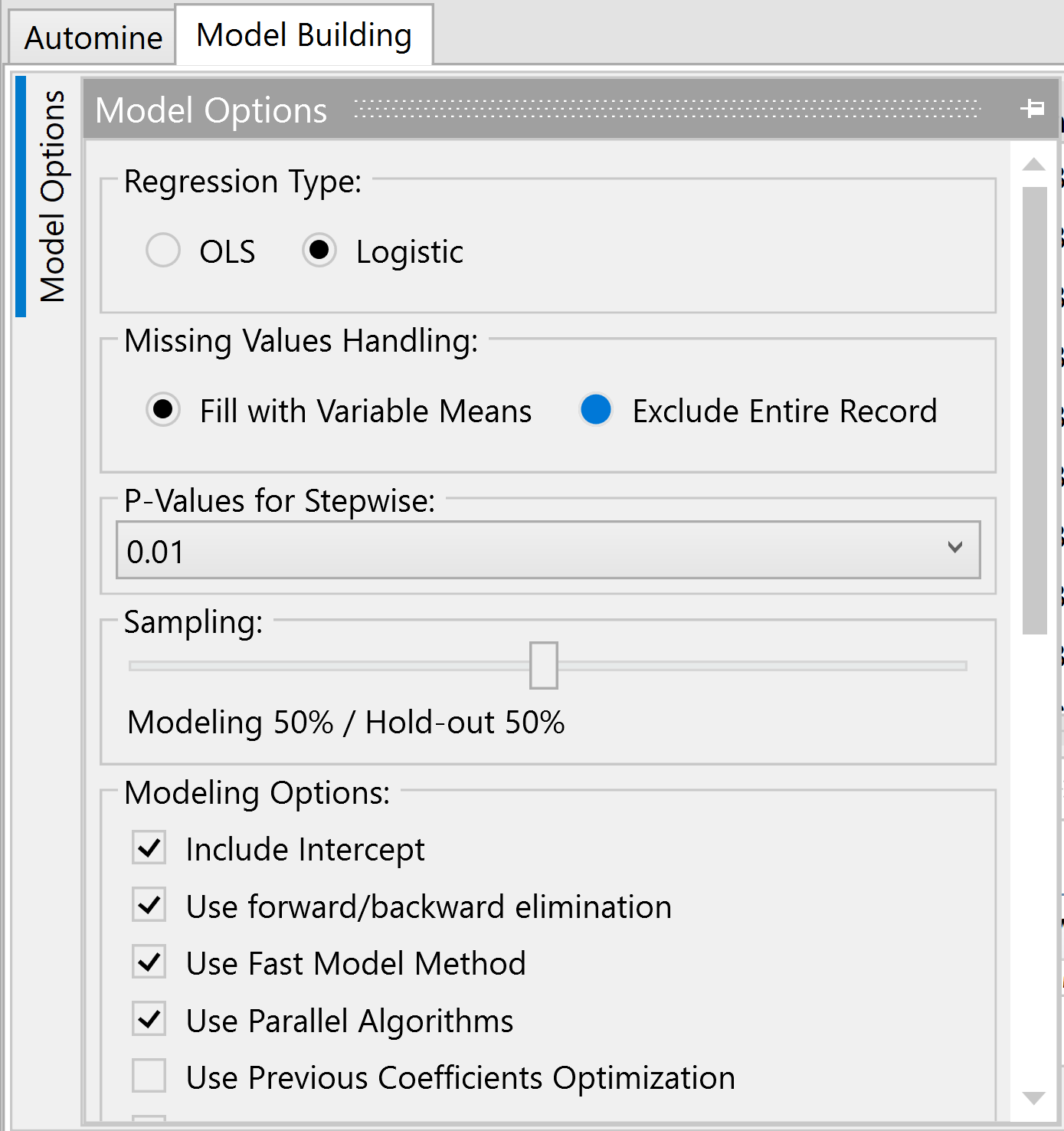
Regression Type - This option is configured automatically when the Y Variable is selected based on the data type of the y variable.
-
- OLS(Ordinary Least Squares)/Linear Regression - If the y variable is a continuous variable, OLS regression will be used. The outcome of the model scoring will be continuous representing the predicted value of the outcome variable.
- Logistic Regression - If the y variable is a binary variable, logistic regression will be used. The outcome of the model scoring will be a value between 0 - 1 representing a probability of the likelihood of the outcome variable to occur.
Sampling - This option adjusts the size of the random sample of records that are used to create the model, and how many records are withheld from development for validation and to evaluate the completed model’s accuracy.
-
- Default setting is modeling 50% / hold-out 50%
- Random samples are chosen using a random number generator when the dataset is loaded into Predict. A number between 0 and 1 is applied to each row of the data. Choosing a 50% sample will result in the software using all records for which the random seed number is below 0.5. For a 30%, all records with a random seed below 0.3 are chosen.
More Model Options
- Missing Values Handling - This is a global setting for missing values. It also serves as the default setting for all missing values. Selecting the Fill with Variable Means option will fill in the missing values for each variable with the average value for that variable. Selecting the Exclude Entire Record option will not replace a missing value with any other value. Rather, it will throw out that record for all variables so that it will not affect the analysis. You can also select missing value rules on a variable by variable basis within the Automine tab.
- P-Values for Stepwise - Provides the ability to change the p-value according to how statistically significant the relationship between the x and y variables should be. The lower the p-value, the more significant the relation is.
- Modeling Options - Control how a model is built and what is displayed in the outcome.
- Include Intercept - Represents an inherent "bias" in the dataset , skewing the predictive results in a particular direction. The option will show or not show the Intercept in the final list of model variables.
- Use Forward/Backward Elimination - Checks to see if any of the variables should be dropped from the model during every model-building step. If a variable that has already entered the model is no longer statistically significant at the chosen p-value, that variable will be removed from the model.
- Use Fast Model Method - Speeds up model development time by eliminating any variables once their significance level falls below the chosen threshold. All variables will be considered during each step if this option is not checked. Automatically-developed models may also take significantly longer to build on large datasets.
- Use Previous Coefficients Optimization - For more information on how the Previous Coefficients Optimization works, contact ri-support@eab.com.
- Show Multicollinearity Diagnostics - Displays any highly correlated relationships between predictor variables. Although correlated variables can exist in a successful predictive model, the values assigned to their coefficients may not accurately estimate each collinear variable’s impact on the Y-variable if the other correlated variables were to be removed. Diagnostics we can include in our output are:
- Variance Inflation Factor and Tolerance: The Variance Inflation Factor (VIF) is equal to the reciprocal of tolerance. In general, the VIF represents the severity of Multicollinearity by measuring how much the variance of a coefficient is increased because of collinearity.
- Covariance of the Estimates: The matrix for the covariance of the estimates can be found in the “Diagnostics” section of the output. In general, a large positive value of covariance can mean that two variables are linearly related; a negative value can indicate that the two variables tend to move in opposite directions.
- Correlation of the Estimates: The correlation matrix can be found in the “Diagnostics” section of the output. The correlation between two estimates is equal to the slope of the regression line between the variables when they have both been normalized. Thus, a value of one indicates a direct correlation, and the closer to + 1 or -1 the value is, the more correlated the two variables are. The sign of the correlation represents a positive or inverse relationship.
- Correlation of the Variables: The correlation matrix can be found in the “Diagnostics” section of the output. The correlation between two variables is equal to the slope of the regression line between the two variables. Thus, a value of one indicates a direct correlation, and the closer to + 1 or -1 the value is, the more correlated the two variables are. The sign of the correlation represents a positive or inverse relationship.
- x’x Matrix: The x’x matrix (also called the variance-covariance matrix) can be found in the “Diagnostics” section of the output. This matrix displays the variances of each variable on the diagonal and the covariances between variables as the off-diagonal values.
- Use Weighted Regression - By checking the “Use weighted regression” box and filling in the “Select Weight Variable” field with a continuous variable, we opt to assign a weight to each row equal to the value of the weight variable for that row. A weight value of zero would, therefore, cause a row to be ignored, and a weight value of two would cause that row to be weighted twice – as though that row appeared twice in the dataset.
- Quantiles - The graphical representation of the model's self test may be changed using this control. Though typically grouping the test records into ten equal bins, this may be adjusted to increase or decrease the number of organizing bins.
- Variables Sorting - The list of variables that appear in the model may be ordered either alphabetically in ascending or descending order, or based upon the reliability of the variable's influence on the Y-variable.
Automine Tab
The Automated Mining (Automine) tab lets users take advantage of Predict’s ability to quickly evaluate all variables against the Y Variable to find any statistical relationships that exist. When a Y Variable is selected, the Automine process automatically tests each variable for relatedness to the Y Variable, and color-codes the variables according to their significance (green = statistically related, red = not related).
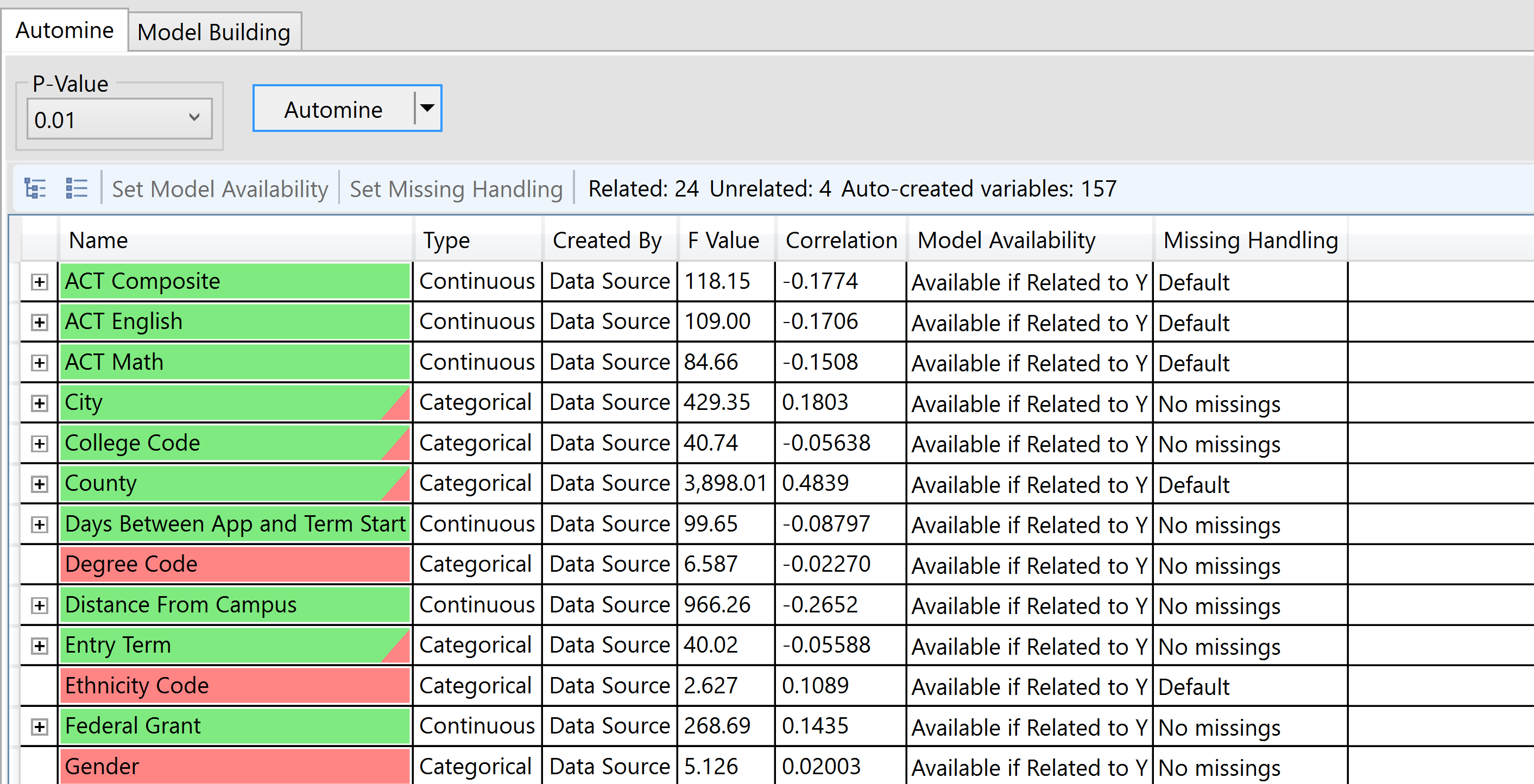
P-Value
The p-value control allows users to establish a p-value threshold for variables that will be considered for inclusion in the model.

Missing Handling
The Automine tab has the option to choose how Predict should handle any missing values of within each variable. The options relating to how the missing value is handled, depend on the type of data being considered. To change how these missing values are handled, select the Missing Handling cell next to the desired variable and select an option from the drop down menu.
Important: When choosing options for handling missing values, remember that excluding multiple records can greatly reduce your sample size for analysis, and could greatly effect the results in your analysis.

- Default- The default setting is to fill in the mean of all values (if the variable is a continuous) and replace with zero if the value in binary.
- Fill with Mean - Takes the average for all known values in that variable, and uses it as a replacement for those values which are missing.
- Exclude Entire Record - Skips over any missing value and does not factor them into the analysis.
Model Availability
A variable’s Model Availability column determines whether a column will or will not appear in the available variables list for modeling. Variables in red are automatically excluded from the available variables as they are not related to the Y Variable, however they can be forced into the variable pool by changing the Model Availability to Available. Variables in green are automatically included in the available variables list. This does not mean they will enter the model, but they will be available for consideration. However, available variables can be forced to not be considered by changing the Model Availability to Exclude. To access this, click on the Model Availability cell of the variable you would like to configure. You can also set the availability of a variable by right click on the name.

Final Regression Model
Once a model has been built, the Final Regression Model section populates with a detailed description of the current model. This output consists of three main sections:
- Predicting - This displays the variables that constitute the model.
- Diagnostics - Provides objective measures evaluating the quality of the model. This is an important section to evaluating the quality of your model.
- Variable Contribution - It lists the variables that constitute the current model in order of their relative contribution to the overall probability score.
Predicting
The Predicting section appears at the top of the Final Regression Model output. It displays the variables that constitute the model, along with their coefficients, standard errors, Wald chi-square t-values, and p-values. The prediction section offers valuable scores that can be used to compare and contrast against the scores of other coefficients.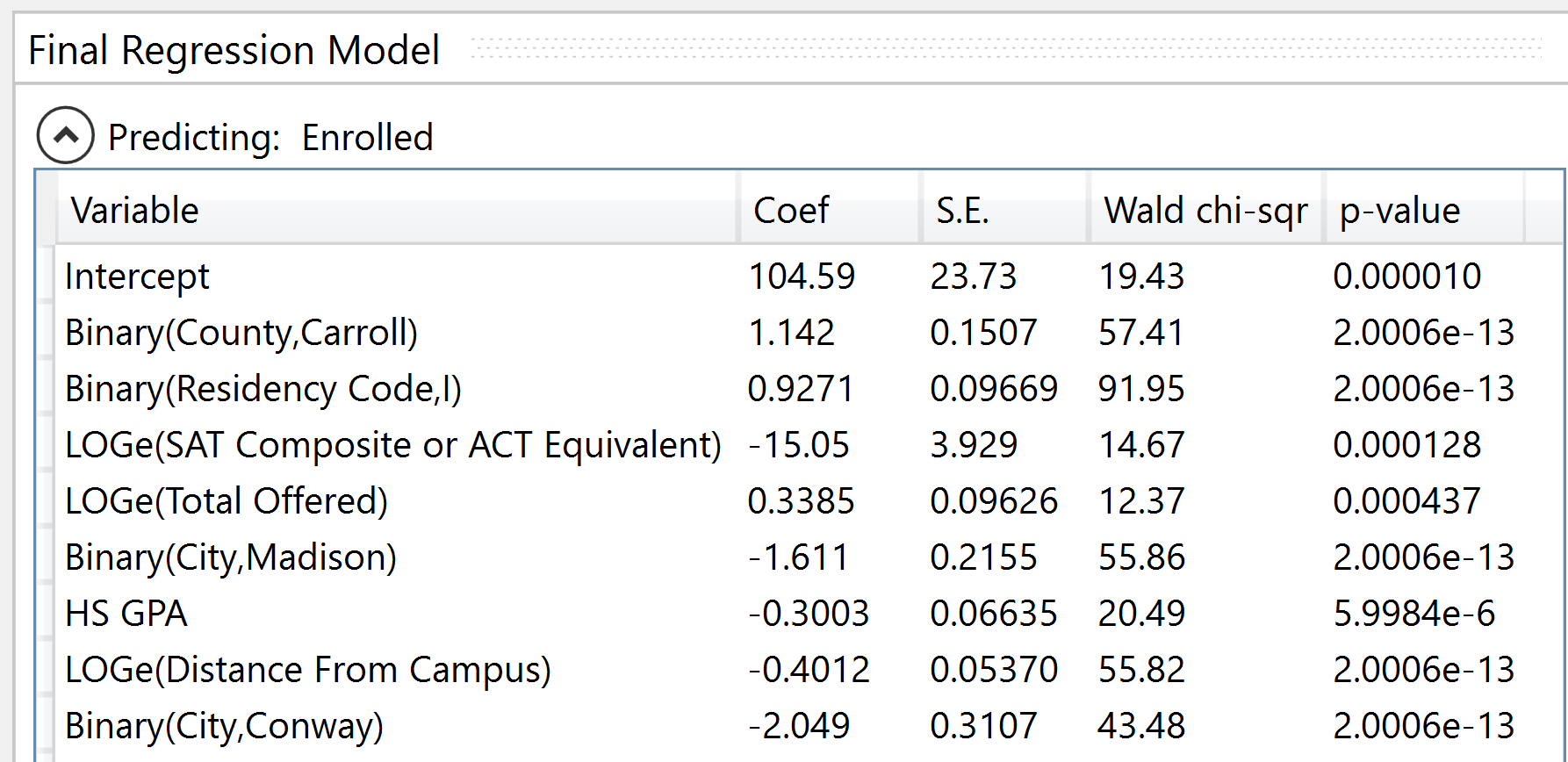
Diagnostics
The Diagnostics section provides objective measures evaluating the quality of the model. These measures include:
- Intercept and Covariates values
- Odds Ratio Estimates for each variable in the model
- 95% Confidence Limits (lower and upper) for each variable in the model
- Percent Concordance
- Percent Discordance
- Percent Tied
- Cox and Snell Pseudo R-squared score
- Somers' D score
- G-K Gamma score
- Kendall's Tau-a score
- C value

Variable Contribution
The Variable Contribution section appears at the bottom of the Final Regression Model output. It lists the variables that constitute the current model in order of their relative contribution to the overall probability score.

Model Steps
After a model is built, the Model Steps tab appears in the bottom left of the Final Regression Model section. During the process of building a model, Predict will check to see if any of the variables should be dropped from the model following each step of the regression analysis. All of the regression analysis steps taken to obtain the current model are available for review in this tab.
If a variable that has already entered the model is no longer statistically significant at the chosen p-value, that variable will be removed from the model.

Model Visualization
The Model Visualization frame offers a graphical representation of the results of testing the model against the holdout sample records. In the default chart, the green bars depict the actual behavior found in the sample. Selecting the Show Actual And Predicted option below the chart will add a set of blue bars depicting the predicted outcome next to the actual outcome.

The type of visualization can be changed using the Chart Type dropdown options.
- Analysis - Orders the probability outcome from highest to lowest, then bins reach record equally into ten columns.
- Lift - Indicates a bins (columns) performance relative to the average performance of the dataset.
- Cumulative Lift - Shows the cumulative percentage of the probable outcome for each decile and the decile before it.
- ROC Curve - Generates a threshold that represents the a record to be a 1 vs. a 0 (true or false).
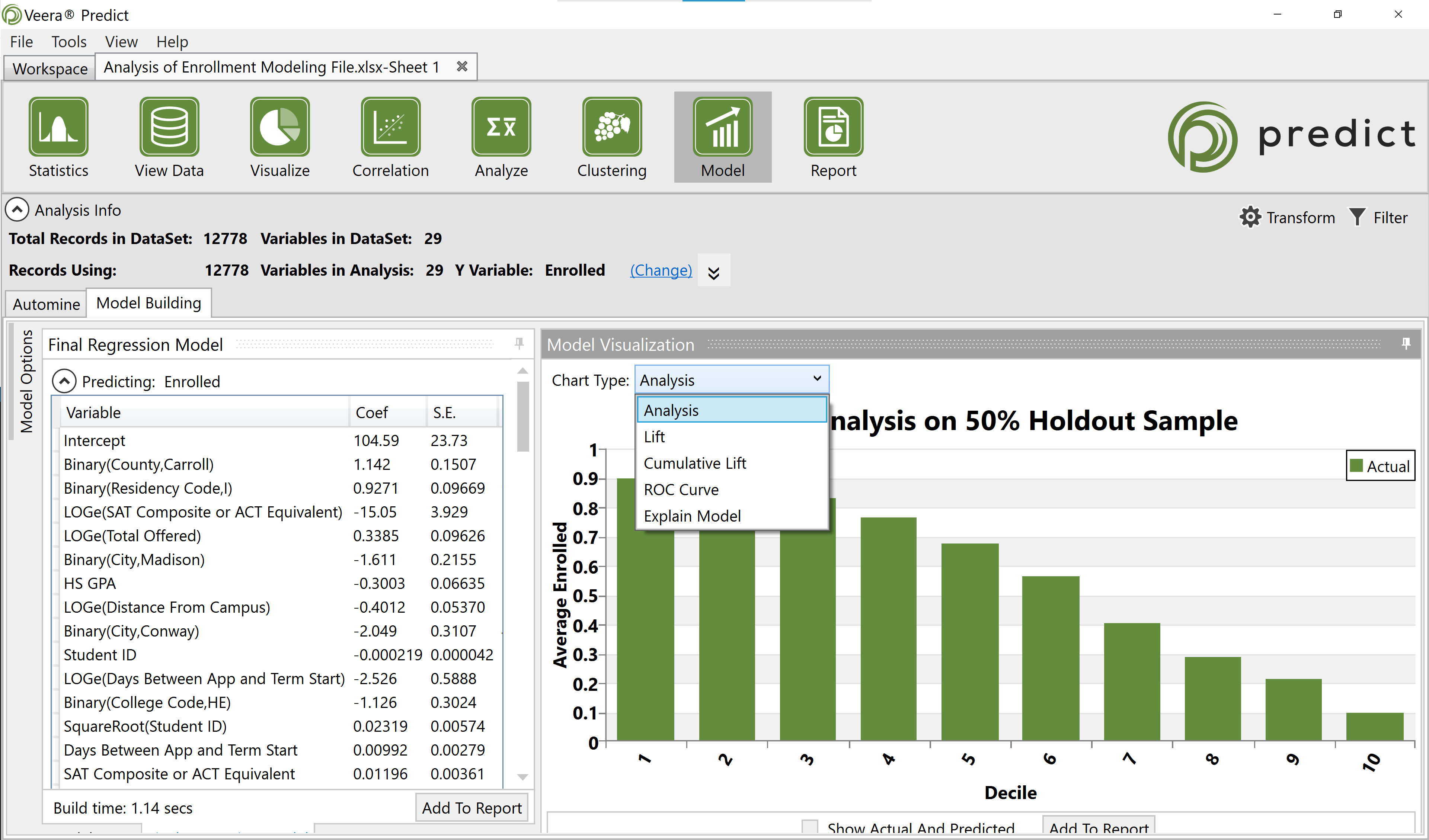
Decile Analysis
The decile analysis takes the total spread of the probability outcome of each record and divides the total population into ten equal bins (deciles). The bars on this chart represent the average probability score for the records placed in each bin. As the order of probability changes the average of each decile will also change. Depending on the dataset, a decile analysis may take the shape of a downward staircase, indicating that the spread of probability is even. However, this staircase shape is not the only metric of model accuracy.

Decile Lift
The decile lift indicates a bins performance relative to the average performance of the dataset. On the y-axis (above), 1.0 represents the point where a decile would perform exactly as the baseline. A Decile lift of 2 would tells us that targeting that population, we would expect that the group of individual would see a rate or amount double the overall average. For example, if a company's employee churn rate averaged 10%, and the first decile had a lift of 2, then that decile would have a group of employee who were actually 20% likely to churn instead of 10%. Another example would be a group of students who would have GPAs of 3.5 instead of the institutional average of 1.75.

Cumulative Lift
The cumulative lift shows the cumulative percentage of the probable outcome for each decile and the decile before it. This would mean that starting with the "10" decile (the top 10% of the population with the highest probability outcome) and moving to the right, each column will average the outcome of all the columns before it. So, if you observe the lift of decile "40", it will give you the average probability results of all the records in deciles 10, 20, 30, and 40. Put another way, the average of a cumulative decile will be that much more accurate than a random sampling of the whole dataset. Note that the average likelihood of the outcome is reduced as you add more deciles. This makes sense, since you are averaging more and more of the probability outcome. The more columns that are averaged together, the more of the total number of observations are being accounted for, and the lower the average outcome for the probability for those total records.

ROC (Receiver Operating Characteristic) Curve
The “ROC Threshold” represents the threshold at which you consider a record to be a 1 vs. a 0. In binary logistic regression, this is the same as an outcome being true or not. ROC curves are only available when your chosen Y-variable is binary.

ROC Options
The “ROC Threshold” represents the threshold at which you consider a record to be a 1 vs. a 0. In other words, when the threshold is at .5, all those records receiving a calculated probability exceeding .5 will be considered 1’s, while those below will be considered 0’s.
Setting a higher threshold will be a more conservative cutoff point, so that, for instance, only those with a probability higher than .75 will be considered 1’s. This is more conservative because it assumes less risk in assigning “positives” or 1’s.
Setting a lower threshold accomplishes the opposite.
Now, the ROC curve itself represents the C statistic for the model in question.

Moving the slider at the bottom of the pane adjusts the cutoff, and based on your chosen threshold, as well as the ROC chart for your model, it will report back your “True Positive” and “False Positive” rates. A “True Positive” is a record that has been assigned a “1” (based on the predicted probability and the selected threshold) and actually was a “1” historically. A “False Positive” is a record that has been assigned a “1” (again, based on the predicted probability and the selected threshold) and historically, was actually a “0.” You would want a high “True Positive” rate, and a low “False Positive” rate.

The basic way to discern whether the ROC Curve is indicating your model is good or bad depends on the shape of the curve. A “flatter” curve indicates that you cannot lower the ROC Threshold without increasing the “False Positive” rate significantly. This is not a desirable characteristic of a model.

A steeper curve (one that tracks closer to the top left corner) indicates that you can choose a lower ROC Threshold without increasing your “False Positive” rate significantly. This is a desirable characteristic of a model.
Create Model Variable

Sometimes it is advantageous to view the probability scores a model produces as if it were a data element in the dataset under analysis. By selecting a memorized model and clicking the Create Model Variable icon, a new column is added to the list of variables - "Probability of Model: <name of model>". In effect, Predict uses the selected model to score each row in the original dataset and stores the resulting probability value in this new column.

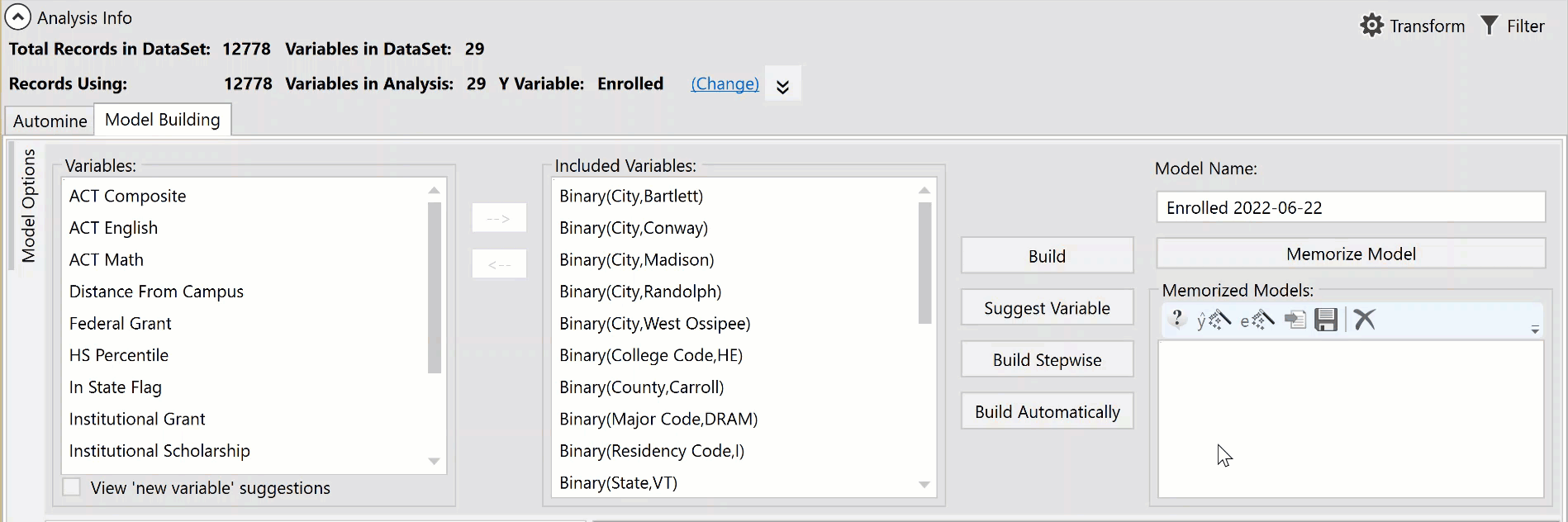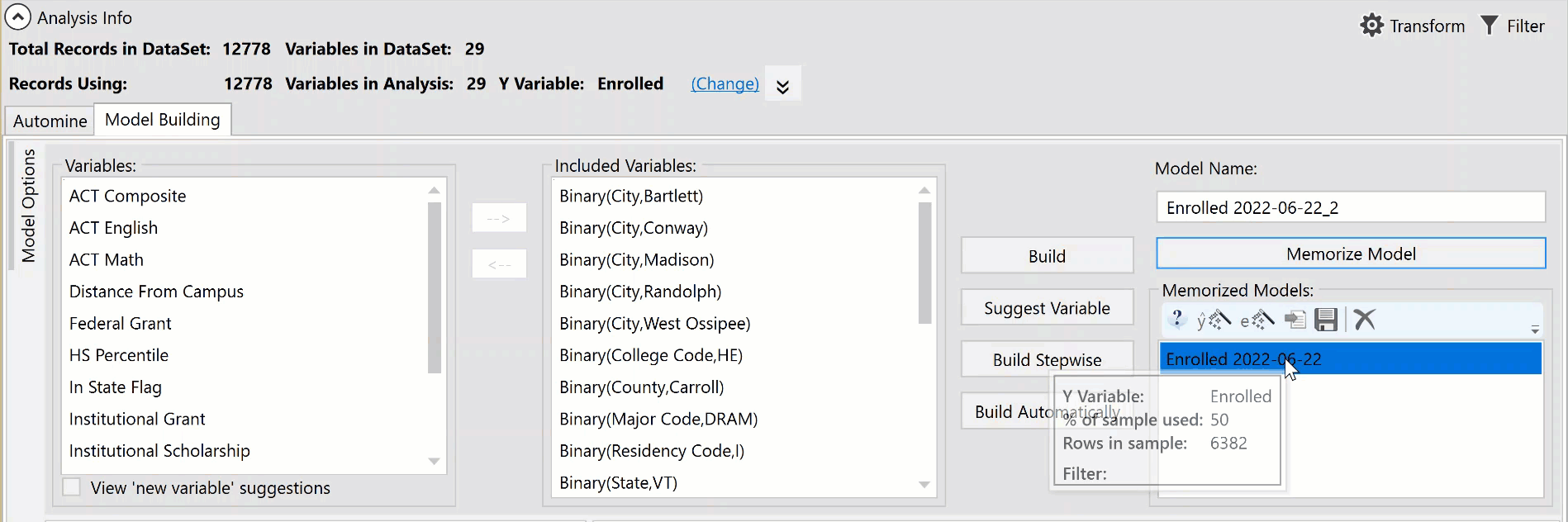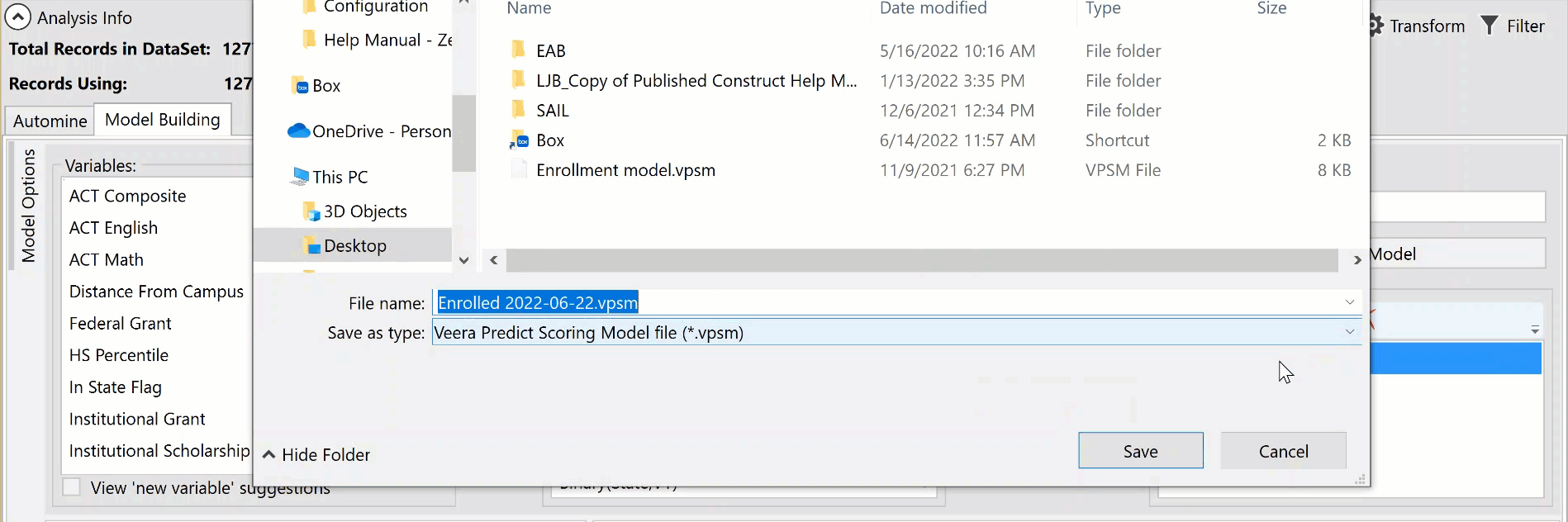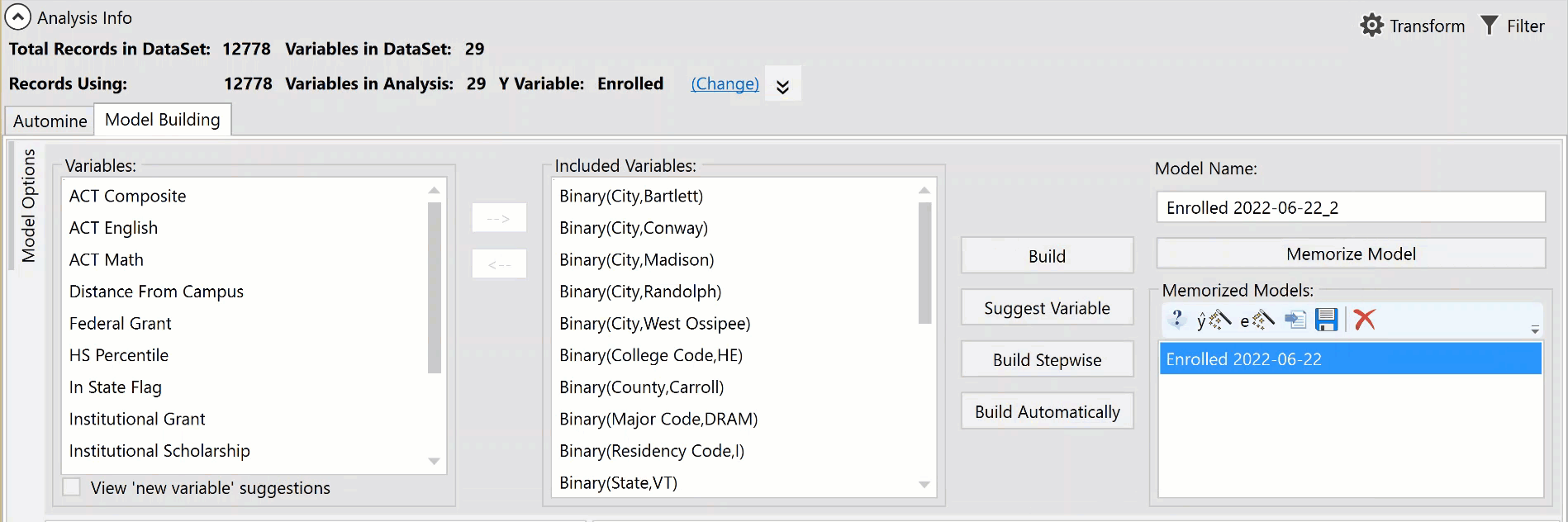
Saving and Memorizing Models
In order to score a dataset using a model, the model first needs to be memorized and then saved. As many model versions as desired can be memorized in a single analysis, but they must be saved individually in order to use for scoring. To do this, select the name of the model you wish to save from the memorized models list. The mini-toolbar will become active, and you can select the Save icon. This opens a file browser and allows you to save your model as a ".vpsm" (Veera Predict Scoring Model) file format. This saves only the formula of the single model. This file is what is used to score datasets which can be done using the Score a File option or by importing the model into Construct.
Note: Memorizing a model is not the same as saving the whole Analysis. To save all your work, go to File > Save Analysis from the main toolbar. This saves a ".vpa" (Veera Predict Analysis) file format containing all analysis information and data.
Comments
0 comments
Article is closed for comments.