
About: This article describes the Statistics subtab in the Analysis tab.
Table of Contents

Introduction
The Statistics subtab is the first page to open once a dataset is loaded into Predict. This subtab allows users to view simple statistics for each of the variables in the dataset, giving a clear and concise way of gaining quick insight. It is recommended to check these statistics at the beginning of your analysis because problems such as data omissions, outlying points, and incorrect data types are often detected here.
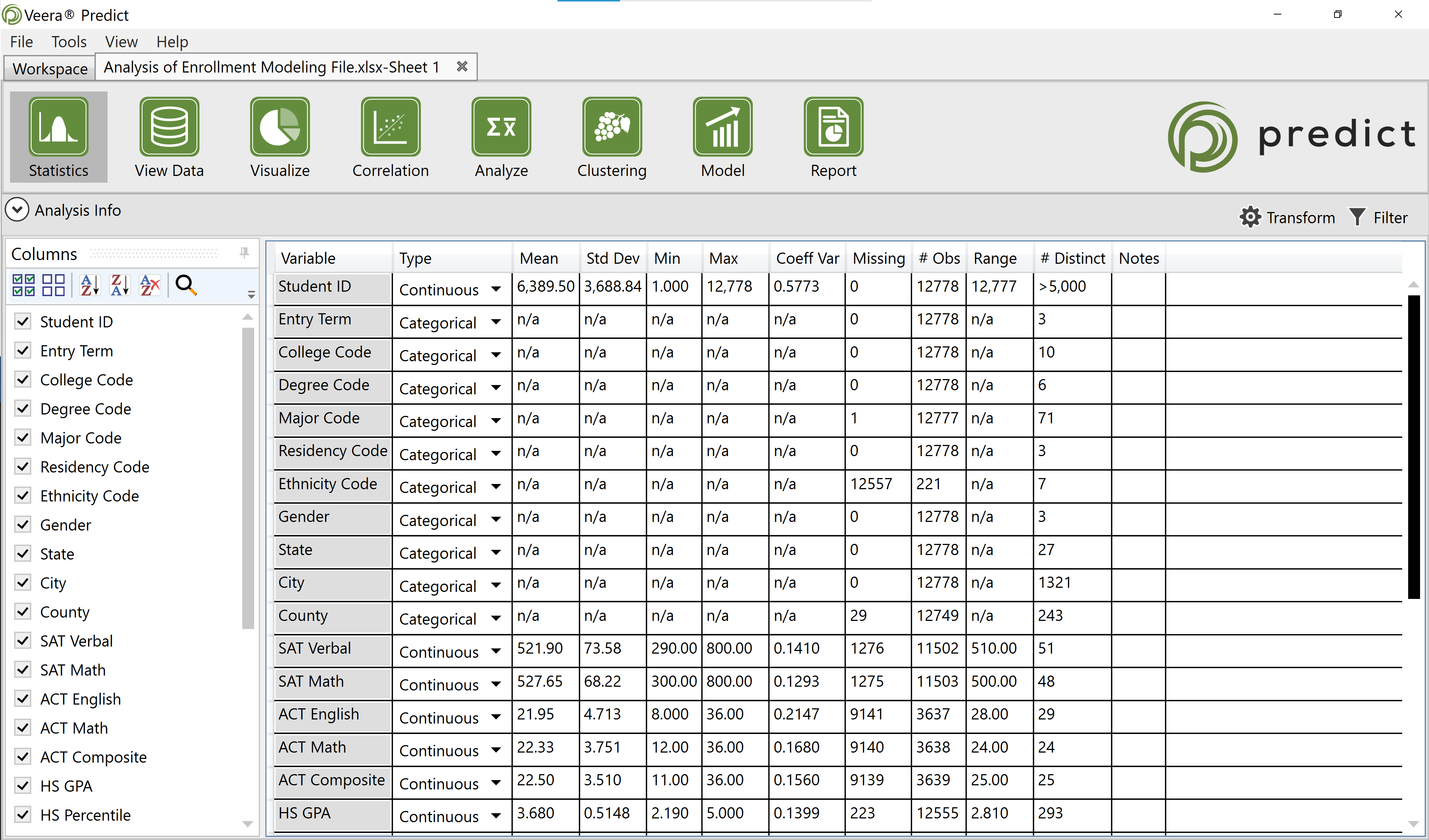
Summary Statistics
The Summary Statistics grid contains information about each variable’s mean, standard deviation, minimum value, maximum value, data type, coefficient of variation, number of missing values, number of observations, number of distinct values, range, and whether a variable is text or not.
- Type (variable type) - This represents the type of variable (continuous, binary, text, etc.).
- Mean - The mean is the average value of all of the observations of one numeric variable.
- Std Dev (standard deviation) - The standard deviation represents the “spread” of data around its mean. A higher value indicates a more spread out data set than a lower value.
- Min (minimum) - The minimum value represents the smallest observation found.
- Max (maximum) - The maximum value represents the largest observation found.
- Coeff Var (coefficient variation) - This represents the ratio of the standard deviation to the mean. The larger this number is, the larger the standard deviation is relative to the mean.
- Missing - This number denotes the number of missing (null) observations for each variable.
- # Obs (total number of observations) - This is the total number of non-null observations for each variable.
- Range - The range represents the difference between the highest and lowest observation for each variable.
- # Distinct (categories) - This represents the number of unique categories within each variable.
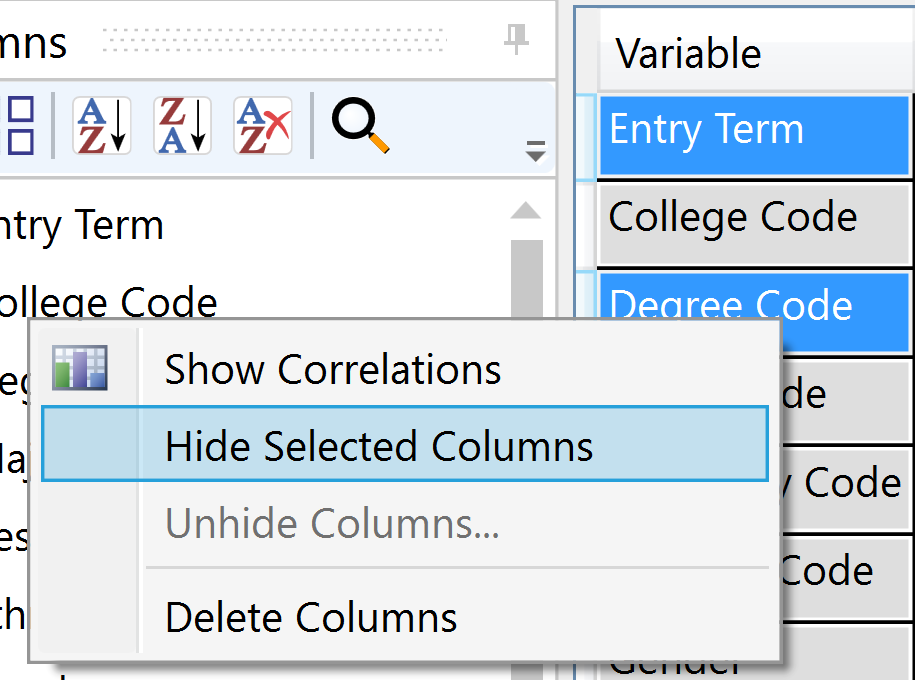
Removing Variables
In cases when users have variables in their dataset that should not be included in any type of analysis, variables can be removed from the dataset (and can be added back if necessary). In the Variable list, right-click on any variable (or multi-select using the Shift or Ctrl keys) and choose Hide Selected Columns. This will remove the variable(s) from reference in every analysis window. The Variables in Analysis section of the Analysis Info window will update to reflect the changes.
However, if you prefer to keep the variable in the analysis, but just exclude it from the modeling process – in the Automine Tab of the Model Subtab, users can right-click on included variable(s) and select "Exclude Variables and their transforms from modeling".
Comments
0 comments
Article is closed for comments.